En el panorama de la inteligencia artificial (IA), en vertiginosa evolución, el concepto de “desaprendizaje” automático ha surgido como un terreno de investigación fascinante y de crucial importancia. Mientras que el paradigma tradicional de la IA se centra en el entrenamiento de modelos para que aprendan de los datos y mejoren su rendimiento a lo largo del tiempo, la propuesta de desaprender va un paso más allá al permitir que los sistemas de IA también olviden o debiliten intencionadamente los conocimientos previamente adquiridos. Este concepto se inspira en los procesos cognitivos humanos, en los que olvidar determinada información es esencial para adaptarse a nuevas circunstancias, dar cabida a nuevas percepciones y mantener un marco cognitivo equilibrado y adaptable.
APRENDIZAJE AUTOMÁTICO FRENTE A DESAPRENDIZAJE AUTOMÁTICO
El aprendizaje automático y el desaprendizaje automático son dos conceptos relacionados con el ámbito de la inteligencia artificial y el análisis de datos. Veamos en detalle qué significa cada término:
Machine Learning (aprendizaje automático)
El aprendizaje automático (Machine Learning, ML) es un subconjunto de la inteligencia artificial que consiste en el desarrollo de algoritmos y modelos que permiten a los ordenadores aprender de los datos y hacer predicciones o tomar decisiones basadas en ellos. Es decir, se trata del proceso de entrenar a una máquina para que reconozca pautas y relaciones en los datos con el fin de hacer predicciones o tomar decisiones acertadas en situaciones nuevas y desconocidas.
El aprendizaje automático suele implicar los siguientes pasos:
- Recopilación de datos: Obtención de datos pertinentes y representativos para la formación y la puesta a prueba.
- Preprocesamiento de datos: Limpieza, transformación y preparación de los datos para el entrenamiento.
- Selección de modelo: Elegir un algoritmo o una arquitectura de modelo adecuados para la tarea en cuestión.
- Entrenamiento de modelos: Introducir los datos en el modelo elegido y ajustar sus parámetros para que “aprenda” de esos datos.
- Evaluación del modelo: Evaluar el rendimiento del modelo con datos no observados para asegurarse de que realiza predicciones correctas.
- Despliegue: Integrar el modelo entrenado en aplicaciones del mundo real para realizar predicciones o tomar decisiones.
Los tipos más comunes de Machine Learning son el aprendizaje supervisado, el aprendizaje no supervisado y el aprendizaje por refuerzo.
Machine Unlearning (desaprendizaje automático)
El “desaprendizaje automático” no es un término ampliamente reconocido en el campo de la IA y el aprendizaje automático. Pero si consideramos el concepto desde una perspectiva metafórica, se podría referir al proceso de eliminación o actualización de los conocimientos adquiridos por un modelo de aprendizaje automático. En cierto sentido, se trata de “desaprender” u “olvidar” ciertas pautas o información que el modelo ha aprendido con el tiempo.

En la práctica, hay varios escenarios en los que podríamos llevar a cabo una especie de “desaprendizaje automático”:
- Deriva conceptual: Con el paso del tiempo, las pautas subyacentes en los datos pueden cambiar, con lo que un modelo entrenado resulta menos fiable o incluso obsoleto. Para adaptarse a estos cambios, puede ser necesario que el modelo se vuelva a entrenar con nuevos datos, “desaprendiendo” así los esquemas obsoletos.
- Confidencialidad y conservación de datos: En situaciones que impliquen datos sensibles, puede ser necesario “desaprender” cierta información del modelo para cumplir la normativa sobre protección de la intimidad o las políticas de conservación de datos.
- Sesgos e imparcialidad: Si un modelo ha aprendido pautas sesgadas a partir de los datos, se puede intentar “desaprender” esos sesgos volviendo a entrenar el modelo con datos más diversos y representativos.
Si bien el “desaprendizaje automático” no es un concepto claramente definido en el contexto del aprendizaje automático, podría referirse a los procesos de actualización, adaptación o eliminación de determinados conocimientos o pautas de un modelo entrenado para así garantizar su precisión, imparcialidad y cumplimiento de los nuevos requisitos.
IMPORTANCIA DE LA ADAPTABILIDAD EN LA IA
La adaptabilidad es la piedra angular de la inteligencia, tanto humana como artificial. Así como el ser humano aprende a desenvolverse en situaciones nuevas y a responder a entornos cambiantes, un sistema de IA aspira a mostrar una capacidad similar para adaptar su funcionamiento a los cambios de circunstancias. El desaprendizaje automático resulta fundamental para fomentar esta adaptabilidad, ya que permite a los modelos de IA deshacerse de información obsoleta o carente de relevancia, lo que les permite centrarse en datos, esquemas y perspectivas actuales y pertinentes, mejorando así su capacidad de generalizar, realizar predicciones y responder con eficacia a nuevas situaciones.

Una de las principales ventajas de la adaptabilidad mediante el desaprendizaje automático es la mitigación de un fenómeno conocido como “olvido catastrófico”, que se produce cuando los modelos de IA se entrenan con nuevos datos y, sin querer, sobrescriben o pierden valiosos conocimientos adquiridos en entrenamientos anteriores. El desaprendizaje automático resuelve este reto al desechar selectivamente la información menos crucial, lo que permite preservar la integridad de los conocimientos previamente aprendidos al tiempo que da cabida a nuevas actualizaciones.
ESTRATEGIAS PARA APLICAR EL DESAPRENDIZAJE AUTOMÁTICO
La aplicación de técnicas de desaprendizaje automático exige enfoques innovadores que logren un equilibrio entre la conservación de conocimientos valiosos y la eliminación de datos obsoletos o poco útiles. Se están estudiando diversas estrategias para alcanzar este delicado equilibrio:
1. Técnicas de regularización:
Los métodos de regularización, como la regularización L1 y L2, se han empleado tradicionalmente para evitar el “overfitting” -exceso de ajuste- en los modelos de IA. La regularización penaliza las ponderaciones elevadas en las redes neuronales, lo que debilita o elimina las conexiones menos importantes y, mediante una aplicación estratégica, orienta a los modelos de IA hacia el desaprendizaje de determinadas pautas, sin perder la información esencial.
2. Asignación dinámica de memoria:
Inspirada en los procesos de la memoria humana, la asignación dinámica de memoria consiste en asignar recursos dentro de un sistema de IA en función de la relevancia y la actualidad de la información, para que el modelo dé prioridad a las experiencias más recientes e impactantes y reduzca de forma gradual la influencia de los datos más antiguos.
3. Redes de memoria y mecanismos de atención:
Las redes neuronales potenciadas por la memoria, que pueden aprender a leer, escribir y olvidar información de una matriz de memoria, simulando el proceso de olvido intencionado, también ofrecen vías para el desaprendizaje automático. Los mecanismos de atención, por su parte, permiten a los modelos de IA centrarse selectivamente en los datos más relevantes y restar importancia paulatinamente a la información menos pertinente.
4. Aprendizaje incremental y adaptación permanente:
El desaprendizaje automático está estrechamente ligado al concepto de aprendizaje incremental, en el que los modelos de IA actualizan continuamente sus conocimientos con nuevos datos al tiempo que desaprenden o ajustan su comprensión de los datos más antiguos, en un enfoque que imita el proceso de aprendizaje permanente de los seres humanos, lo que permite a los sistemas de IA acumular y perfeccionar conocimientos con el tiempo.
APLICACIONES DEL DESAPRENDIZAJE AUTOMÁTICO
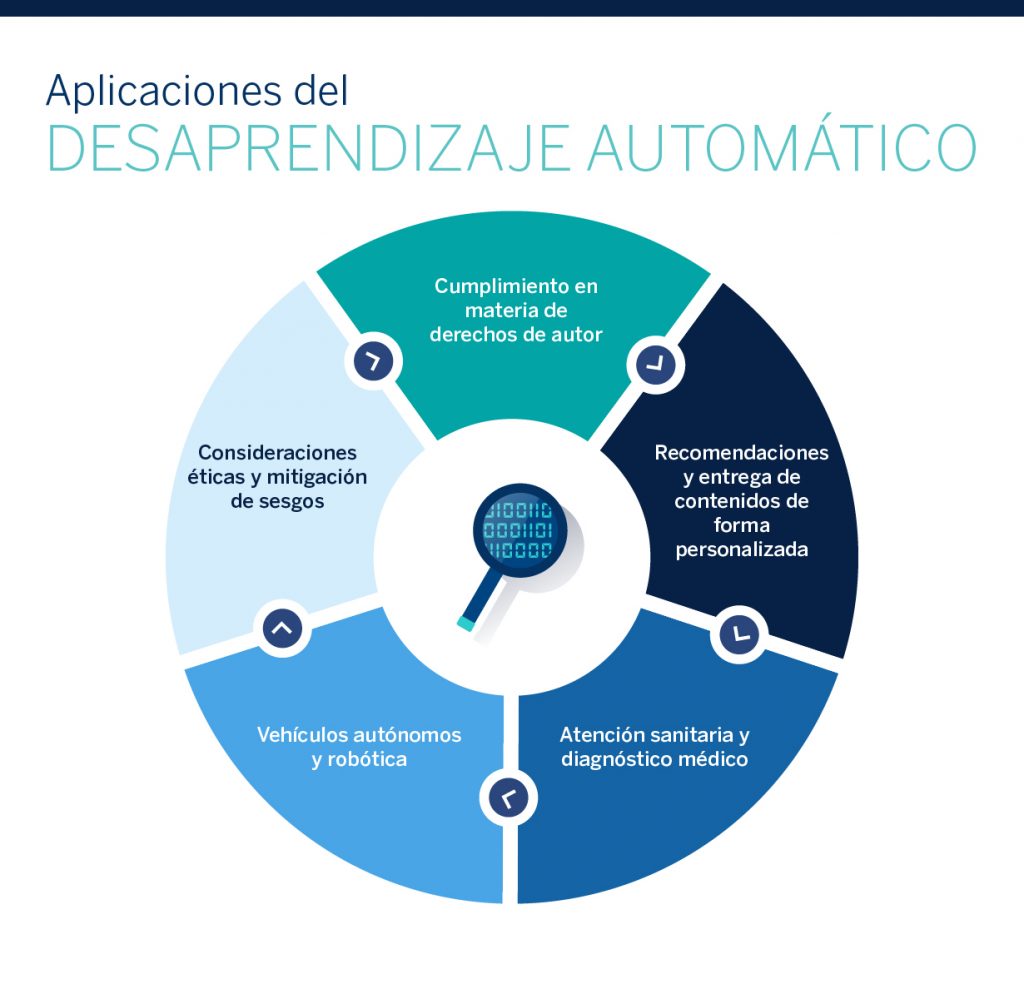
El concepto de desaprendizaje automático tiene implicaciones de gran alcance en diversos ámbitos y aplicaciones de la IA:
1. Cumplimiento en materia de derechos de autor:
Los modelos de IA se entrenan con una gran cantidad de datos, incluidos materiales protegidos por derechos de autor. Si se impulsa la eliminación de los contenidos protegidos por derechos de autor de los modelos de IA, el desaprendizaje automático podría favorecer el cumplimiento de la normativa en este ámbito, lo que podría ser visto como un paso positivo por los titulares de derechos de autor y los defensores de una mayor protección de la propiedad intelectual.
2. Recomendaciones y entrega de contenidos de forma personalizada:
En el ámbito de los sistemas de distribución y recomendación de contenidos, el desaprendizaje automático puede mejorar la personalización al permitir que los modelos de IA olviden las preferencias obsoletas de los usuarios, lo que garantiza que las recomendaciones siguen siendo oportunas y reflejan la evolución de los gustos de los usuarios.
3. Atención sanitaria y diagnóstico médico:
Los sistemas de IA sanitaria podrían aprovechar el desaprendizaje automático para adaptarse a cambios en las condiciones de los pacientes y en los conocimientos médicos. Al desaprender los datos médicos obsoletos y dar prioridad a los resultados de las investigaciones más recientes, los modelos de IA podrán ofrecer diagnósticos más fiables y actualizados.
4. Vehículos autónomos y robótica:
El desaprendizaje automático podría ser clave en sistemas autónomos como los coches autónomos y los drones. Al desaprender los datos obsoletos de los sensores o las características del entorno, los sistemas pueden tomar decisiones en tiempo real basadas en información actual y oportuna.
5. Consideraciones éticas y mitigación de sesgos:
El desaprendizaje automático puede resolver problemas éticos de la IA, sobre todo relacionados con los sesgos y la imparcialidad. Al desaprender pautas o vínculos sesgados presentes en los datos de entrenamiento, los modelos de IA podrán reducir la persistencia de decisiones y resultados injustos.
REPERCUSIONES Y CUESTIONES ÉTICAS
Si bien el desaprendizaje automático ofrece numerosas ventajas, también plantea interrogantes y cuestiones éticas:
1. Transparencia y rendición de cuentas:
El desaprendizaje automático podría entorpecer la transparencia y facilidad de comprensión de los sistemas de IA, ya que, si se permite que los modelos olviden intencionadamente cierta información, quizá resulte difícil rastrear el proceso de toma de decisiones y exigir responsabilidades a los creadores de la IA por su actuación.
2. Confidencialidad y conservación de datos:
El olvido intencionado de datos está en consonancia con los principios de confidencialidad, ya que los modelos de IA pueden descartar información sensible o personal una vez agotada su utilidad. No obstante, sigue siendo difícil encontrar el equilibrio adecuado entre el desaprendizaje en aras de la privacidad y la conservación de los datos a efectos de rendición de cuentas.

3. Consecuencias imprevistas:
El desaprendizaje automático, si no se controla con cuidado, podría tener consecuencias imprevistas. Los sistemas de IA podrían olvidar información crítica, lo que daría lugar a decisiones erróneas o a un menor rendimiento en contextos específicos.
4. Amplificación de sesgos:
Si bien el desaprendizaje automático puede reducir los sesgos, conviene tener en cuenta la posibilidad de que se amplifiquen inadvertidamente mediante la introducción de nuevos sesgos o el falseamiento de la comprensión de determinados datos por parte del modelo.
EL CAMINO POR RECORRER: RETOS Y PERSPECTIVAS
La exploración del desaprendizaje automático aún está en sus inicios, y quedan numerosos retos por delante:
1. Desarrollo de algoritmos eficaces:
Es complejo diseñar algoritmos que permitan a los modelos de IA desaprender de forma eficaz e inteligente. Es preciso un enfoque innovador para conciliar la conservación de conocimientos valiosos con la eliminación de información obsoleta.
2. Granularidad y contexto:
Resulta esencial determinar la granularidad y el contexto adecuados para desaprender. Los modelos de IA deberán identificar qué datos, características o relaciones específicas conviene desaprender para optimizar su rendimiento.

3. Adaptabilidad dinámica y contextual:
El desaprendizaje automático deberá permitir una adaptabilidad dinámica y contextual que facilite que los sistemas de IA olviden la información en función de la evolución de las prioridades y las tendencias emergentes.
4. Marcos éticos:
Como ocurre con cualquier desarrollo de la IA, la aplicación del desaprendizaje automático debe seguir marcos éticos bien definidos, fundamentales para garantizar la rendición de cuentas, la imparcialidad y la transparencia.
VISIÓN A FUTURO
Aunque el camino hacia la plena realización del desaprendizaje automático está jalonado de retos y cuestiones éticas, encierra la promesa de liberar nuevas dimensiones del potencial de la IA. A medida que investigadores y profesionales sigan estudiando estrategias, algoritmos y aplicaciones innovadoras, el desaprendizaje automático podría allanar el camino a una generación de sistemas de IA más matizados, más sensibles al contexto y más conscientes de la ética. En última instancia, la integración del desaprendizaje automático en el ámbito de la IA podría dar lugar a sistemas que no solo aprenden y recuerdan, sino que también se adaptan y olvidan, reflejo de la delicada dinámica de la cognición humana.
Ahmed Banafa, Autor de los libros:
Secure and Smart Internet of Things (IoT) Using Blockchain and AI
Comentarios sobre esta publicación